
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- gradient descent
- 코테
- 알고리즘
- 머신러닝
- transformer
- Linear Model
- 일기
- Django
- prompt engineering
- GPT
- BFS
- LLM
- 파이썬
- Python
- attention
- 부스트캠프
- 코딩테스트
- LeetCode
- ChatGPT
- Deeplearning
- dl
- machinelearning
- NLP
- 프로그래머스
- rnn
- deque
- Programmers
- 프롬프트
- 기계학습
- Linear Regression
- Today
- Total
크크루쿠쿠
[데이터 제작] 5. 원시 데이터의 수집과 가공 본문
원시 데이터란?
과제를 해결하기 위해 수집한 데이터 로써 주석 단계를 거치지 않은 상태의 데이터
무엇을 검토해야 하는가? ->

원시 데이터의 종류
원시 데이터 수집 방식에 따른 분류

기존 데이터가 있다면 사용하는것이 최고다
원시 텍스트 데이터 사용역(장르)에 따른 분류
문어 -> 신문기사, 소설, 수필, 논문, 잡지, 보고서
구어 -> 일상 대화, 연설, 강연 (준구어 -> 방송 대본, 영화 대본 등)
전사하는것이 힘든 과정이라 준구어 데이터도 많이 사용한다(차선책).
웹 -> SNS, 커뮤니티 게시판, 메신저 대화, 블로그, 이메일 등
웹 같은 경우는 문어의 특성을 띄기도 하고 구어의 특성을 띄기도 한다.
원시 텍스트 데이터의 메타 정보
텍스트 외에 텍스트를 설명하는 정보
텍스트ID, 이름, 저장 정보, 매체 정보, 주석 정보, 출처 등등..

원시 데이터 수집 시 고려 사항
획득 가능성
획득이 불가능하거나 통제 불가능하다면 바람직 하지 않다.
획득이 용이하더라도 비용이 크면 선정하기 어렵다.
데이터 균형과 다양성
개체의 다양성, 목적 및 상황의 다양성, 시간별, 종류별, 사람별, 지역별 다양성
데이터 label 분포가 다양한가?
신뢰성
데이터의 품질이 신뢰할 수 있는지 검토
법 제도 준수
사생활 보호가 필요한 항목 획득 시 법적, 기술적 절차를 거친 데이터를 활용한다. 그렇지 못한 데이터는 정제 과정에서 처리가 되어야 한다.

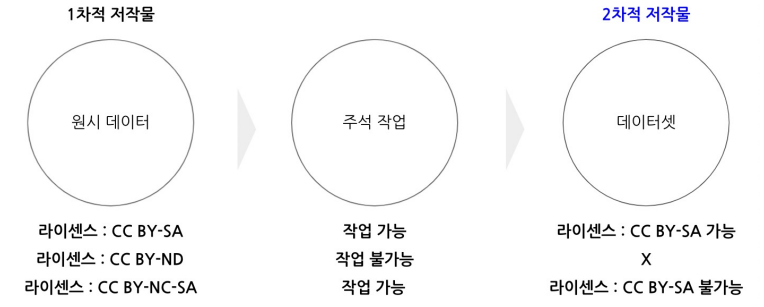
저작권
원시 데이터에 주석 작업을 하는 경우, 결과물은 2차적 저작물로 간주되기 떄문에 라이센스틑 원시 데이터를 따른다.
데이터 윤리
법적으론 문제가 없으나 지켜야 할 것들

원시 데이터 전처리
전처리는 크게 세가지를 한다.
추출 대상 확인
- 메타 정보
- 주석 대상 텍스트
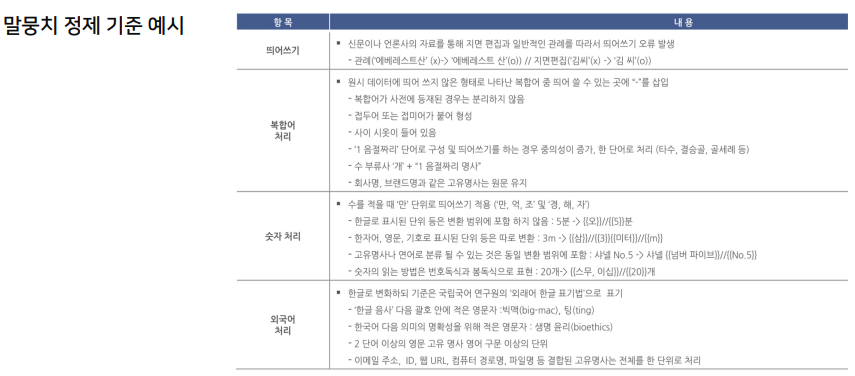
정제 대상 확인
- 숫자, 외국어, 기호, 이모지
- 띄어쓰기, 맞춤법, 오탈자
- 개인 정보
- 문장 분리
불필요 요소 제거 및 변환
- 개인정보 비식별화
- 비윤리적 표현 정제
원시 데이터의 가공
주석 (annotation, labeling)
원시 데이터를 가공하여 원하는 정보를 부착하는 작업, 텍스트의 단순 분류, 개체명 정보 등등을 문자열에 직접 주석 할 수 있음.
주석 도구의 종류
수집과 가공이 가능하다.
1. 구글 스프레드 시트 (추천)
여러명 작업 가능, 데이터 관리 용이, csv나 tsv 형태로 export 가능

2. 구글 폼
단순 분류 문제 등 복잡한 주석이 필요하지 않은 경우에 적합.
결과를 스프레드 시트로 확인 가능
작업자 모집에도 활용

3. Brat
오픈 소스 데이터 주석기
너무 오래됐다..
4. Doccano
NER, 감성분석, 기계 번역 등 주석 기능 제공
서버 또는 로컬에 설치해 사용

5. Tagtog
웹 기반 주석 도구
무료 버전 사용 시 데이터 공개해야함

'DeepLearning > 부스트캠프 AI Tech' 카테고리의 다른 글
| [데이터 제작] 7. 데이터 구축 가이드라인 작성 기초 (0) | 2021.11.11 |
|---|---|
| [데이터 제작] 6. 데이터 구축 작업 설계 (0) | 2021.11.10 |
| [데이터 제작] 4. 자연어 처리 데이터 소개 (2) (0) | 2021.11.09 |
| [데이터 제작] 3. 자연어 처리 데이터 소개 (1) (0) | 2021.11.08 |
| [데이터 제작] 2. 자연어처리 데이터 기초 (0) | 2021.11.08 |



