
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 머신러닝
- 일기
- Python
- 코딩테스트
- Programmers
- Linear Model
- 부스트캠프
- 알고리즘
- LeetCode
- 프로그래머스
- transformer
- Django
- NLP
- Linear Regression
- dl
- GPT
- BFS
- attention
- gradient descent
- 기계학습
- ChatGPT
- 파이썬
- prompt engineering
- rnn
- LLM
- machinelearning
- deque
- 프롬프트
- 코테
- Deeplearning
- Today
- Total
크크루쿠쿠
[Week2] DL Basic [Day1] 본문
Historical Review
Introduction
- Disclaimer

분야도 많고 각자만의 특징이 다 다르다
- What make you a good deep learner?
1. Implementation Skills
구현 능력
2. Math Skills
이번주 수업에서 주로 다룰 내용
3. Knowing a lot of recent Papers
요즘 대세? 어떤 발전이 있는가
하지만 이번주 수업은 아님
인공지능
인간의 지능을 모방하는것

ml -> 학습을 data를 통해 하는 것
dl -> model 이 neural network를 사용하는 것
Key Components of Deep learning
1. The data that the model can learn from
- classification
- semantic segmentation
- detection
- pose estimation
- visual QnA
2. The model how to transform the data
AlexNet, GoogLeNet, ResNet ...
3. The loss function that quantifies the badness of the model
proxy of what we want to achieve
loss가 줄어든다고 항상 우리 목표치는 X -> 학습하지 않은 data에도 잘 작동하게 하기 위해
4. The algorithm to adjust the parameters to minimize the loss
-> 논문을 확인할 때 이 4가지를 확인하면 이해하기가 더 쉬움
Historical Review
2012 - AlexNet
CNN
Imagenet 대회에서 첫 DL 1등 -> 이후 DL이 매년 우승 -> DL 판도가 바뀜
2013 - DQN
알파고 시조 모델? 강화학습 모델
야타리라 부르는 게임을 학습
오늘날의 Deepmind가 있게 한 모델
2014 - Encoder / Decoder

기계어 번역의 trend
2014 - Adam Optimizer
이젠 대부분의 학습 시 Adam을 사용
왜? -> 성능이 그냥 좋음
hyperparameter를 찾는방법은 computing resource를 매우 크게 잡아먹음
-> 그냥 Adam 쓰자
2015 - Generative Adversial Network
매우 중요 수업을 따로 할 예정
2015 - Residual Networks
이 연구 덕분에 DL의 DL이 가능해졌다.
Network를 깊게 쌓으면 test data에서 성능이 안나왔었는데 이 ResNet이 나온 이후로 더 깊게 쌓을 수 있게 해줌
2017 - Transformer
대부분의 RNN model을 대체함
2018 - BERT
fine-tuned NLP models 가 중요
많은 단어들로 학습된 model을 fine-tuned해 사용
2019 - BIG Language Models
GPT-X
2020 - Self Supervised Learning
SimCLR : a simple framework for contrastive learning of visual representations
학습 data 외에 unsupervised data를 사용하겠다.
-> label을 모르는 data들을 학습에 같이 사용함
Neural Networks & Multi-Layer Perception
Neural Networks
Neural networks are computing systems vaguely inspired by the biological neural networks that constitute animal brains. -wikipedia
모든것이 모방은 아님 -> Backpropagation 같은 경우는 뇌에서 일어나는 과정이 아님.
비행기도 꼭 새처럼 날 필요는 없는것처럼 꼭 인간의 뇌를 전부 모방할 필요는 없음.
작금의 NN 방법이나 trend는 인간의 뇌를 모방해서 잘 작동하는 것은 아님.
-> Neural networks are function approximatiors that stack affine transformations followed by nonlinear transformations.
Linear Neural Networks

하지만 세상은 1차원으로만 이루어져 있지 않다.
-> 행렬을 사용하면 된다.
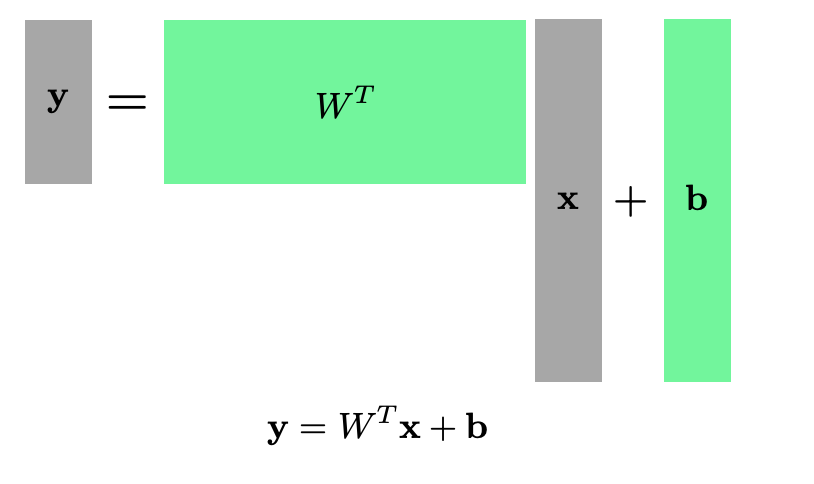
What if we stack more?
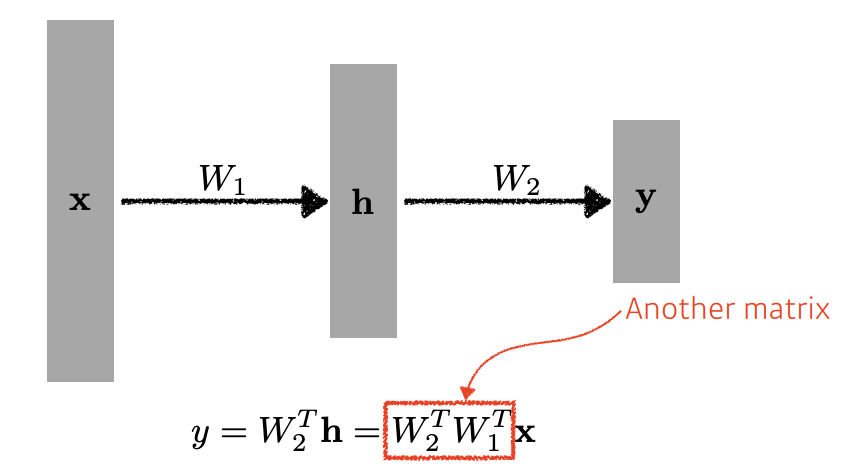
하지만 이는 1단계만 stack 한것과 다르지 않음
-> nonlinear 한 변환이 중간에 필요함
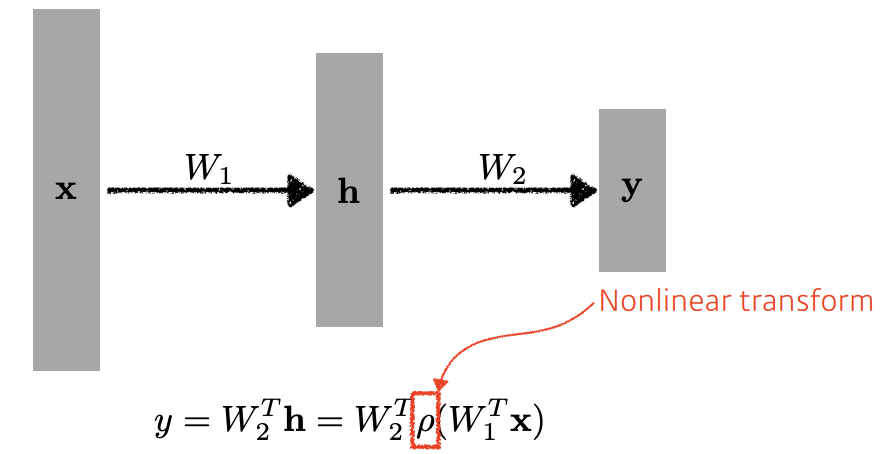
이 변환을 Activation functions 라 함
어떤 Activation function이 좋은가? -> 문제마다 다름.
하지만 이를 사용해서 깊은 네트워크가 효과를 보게 해줌.
Multilayer Feedforward Networks are Universal Approximators
-> 한개의 hidden layer 만으로도 대부분의 문제를 풀 수 있음.
-> But 찾는 방법은 알 수 없다.
Multi-Layer Perceptron
3층 이상의 model
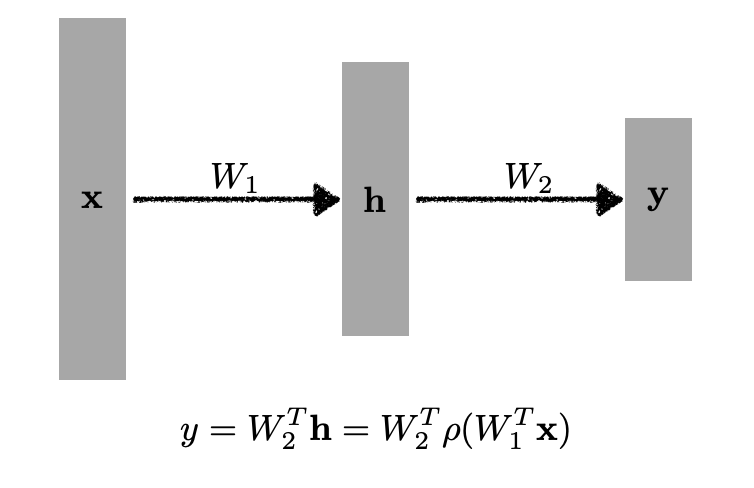
hidden layer를 더 쌓아도 됨.
'DeepLearning > 부스트캠프 AI Tech' 카테고리의 다른 글
| [Week2] DL CNN(Convolutional Neural Network) [Day3] (0) | 2021.08.11 |
|---|---|
| [Week2] DL Basic Optimization[Day2] (0) | 2021.08.10 |
| [Week1] Python Basics for AI & AI Math_Overview [Day5] (0) | 2021.08.08 |
| [Week1] Python Basics for AI & AI Math_Overview [Day4] (0) | 2021.08.05 |
| [Week1] Python Basics for AI & AI Math_Overview [Day3] (0) | 2021.08.04 |



