
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Linear Model
- dl
- deque
- 프로그래머스
- gradient descent
- 부스트캠프
- ChatGPT
- attention
- Programmers
- 코테
- Python
- GPT
- Deeplearning
- NLP
- rnn
- 머신러닝
- Django
- LLM
- BFS
- LeetCode
- 파이썬
- Linear Regression
- 일기
- 기계학습
- 알고리즘
- machinelearning
- 코딩테스트
- prompt engineering
- 프롬프트
- transformer
- Today
- Total
크크루쿠쿠
[Week2] DL CNN(Convolutional Neural Network) [Day3] 본문
[Week2] DL CNN(Convolutional Neural Network) [Day3]
JH_KIM 2021. 8. 11. 13:33Convolution은 무엇인가?
Convolution
- Continuous convolution
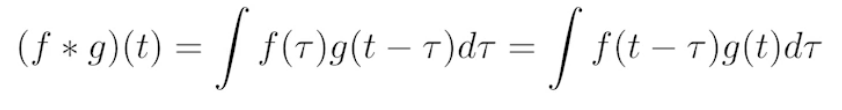
- Discrete convolution

- 2D image convolution (우리가 아는 것)

padding 이나 stride를 고려하지 말고 보면

여러개의 feature map이 생기는 이유?
-> 여러개의 filter를 가짐으로써 가질 수 있다.
Stack of Convolutions
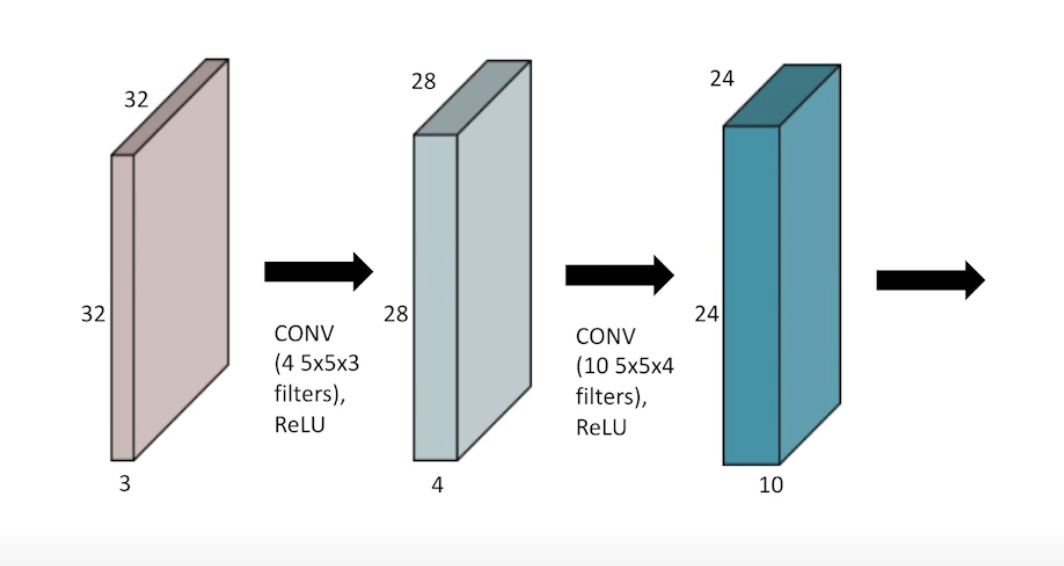
parameter 수는?
1차 conv -> 5x5x3x4
kernel size * input channel * output channel 로 parameter 수를 구할 수 있음.
CNN

고전적인 CNN model -> fc 가기 전에 feature를 뽑는과정임
-> parameter 수를 줄이고 generalize performance 를 위해 fully connected layer를 줄이는 방향으로 감.
ex) googlenet

Stride
얼만큼 옮기는가?

2D로 가게 된다면 x축과 y축 변수 2개 필요
Padding
끝 값들도 conv 하기 위해 덧대는 요소들

Convolution Arithmetic


fully connected 부분을 보면 parameter 수가 급증하는것을 볼 수 있음
-> 어떻게 줄이지?
1x1 Convolution
dimension을 줄이는 방법.

더 깊게 쌓으면서 parameter 수를 줄일 수 있음.
Modern CNN
ILSVRC
이미지넷 대회
1000개의 카테고리
over 1M images

AlexNet

2개로 나누어진 network
-> GPU 성능으로 인해서
11x11 filter -> 왜? parameter만 늘어나는데 ( 나중에 이유 나옴 )
8layers network
- Key ideas
1. ReLU activation 사용 -> Overcome the vanishing gradient problem
2. 2GPU
3. Local response normalizaion, Overlapping pooling
4. Data argumentation
5. Dropout
-> 현재는 당연한 것이지만 2011년에는 최초 시도들이였음.
VGGNet
3 x 3 convolution filters 만 사용.
- Why 3 x 3 convolution?
filter 크기가 커질수록 하나의 filter로 고려되는 input의 크기가 커짐 -> receptive field가 커짐

같은 receptive field로 # of params를 줄일 수 있음.
GoogLeNet

같은 모양이 반복 -> Network-in-network (NiN)
Inception blocks

Concatenation도 중요하지만 중간중간에 있는 1x1 Conv가 매우 중요
-> can be seen as channel-wise dimension reduction

3x3 을 씀으로써 params 수를 줄였지만 중간에 1x1를 넣음으로써 더 줄일 수 있게 됨
receptive field 는 같음.
ResNet
generalizaiton performance
deeper neural networks are hard to train
-> 깊어져도 더 성능이 올라가는것이 아님
- identity map (skip connection)

-> 더 deep 하게 쌓아도 학습이 가능한것을 보여줌.

- Bottlenect architecture

DenseNet
ResNet idea 에서 더하는것이 아닌 함께가는것
-> DenseNet uses concatenation instead of addition
하지만 channel수가 계속 커짐
1x1 conv를 사용해서 줄여줌
-> Dense Block 으로 늘리고 1x1로 줄이는 방식
---> ResNet 이나 DenseNet을 사용시 효과가 좋음.
Computer Vision Applications
Semantic Segmantation

이미지를 픽셀별로 분류하는 것.
자율주행에 활용이 많이 됨. -> 자동차 앞에 무엇이 있는지 알아야함.
Fully Convolutional Network

dense layer가 없다.
이러한 과정을 convolutionalization 이라 한다.
기존 CNN 과 params 자체는 완벽히 일치함.

근데 왜 할까?
-> Transforming fully connected layers into convolution layers enables a classification net to output a heatmap
- 어떠한 size로 input으로 넣더라도 dimension이 줄기 때문에 늘려야함(?)
1. Deconvolution (conv transpose)
convolution의 역연산
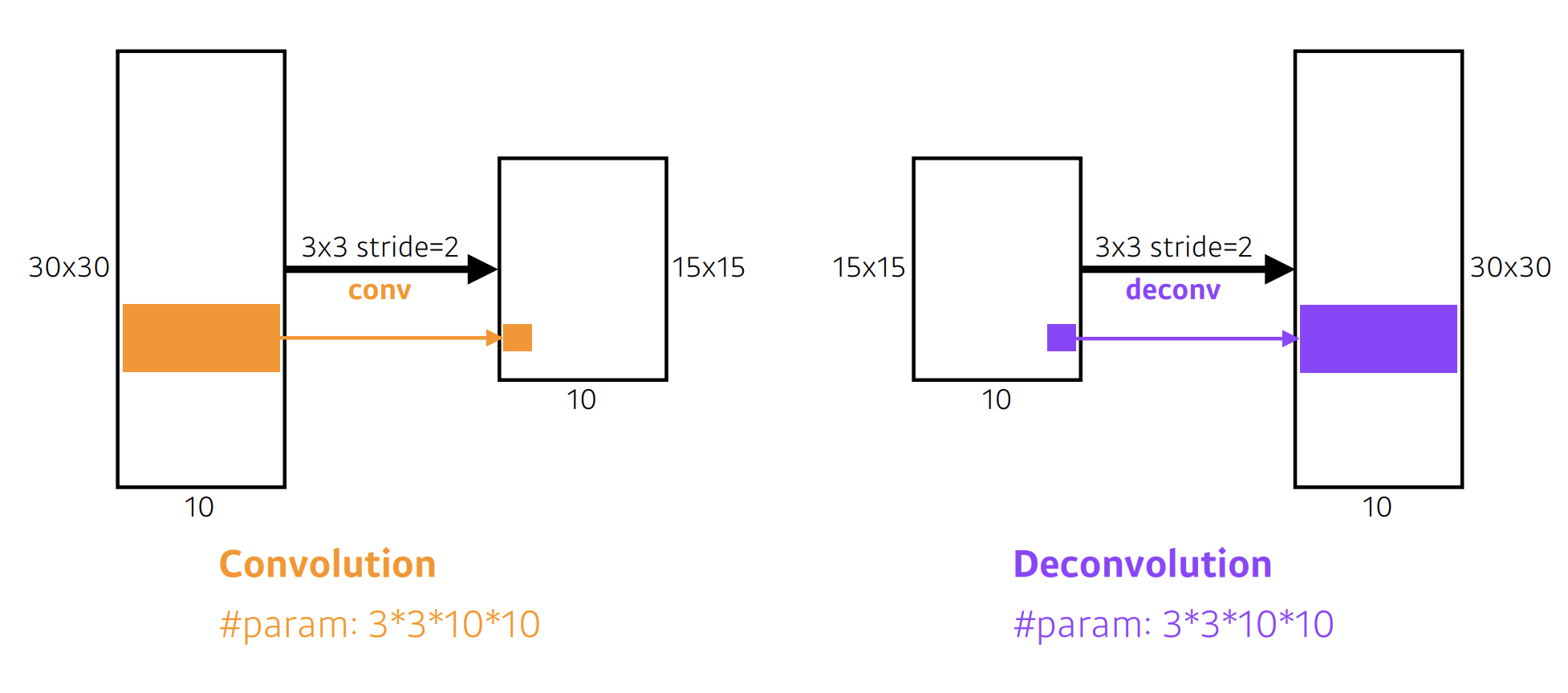
역으로 복원하는건 불가능함

- Results
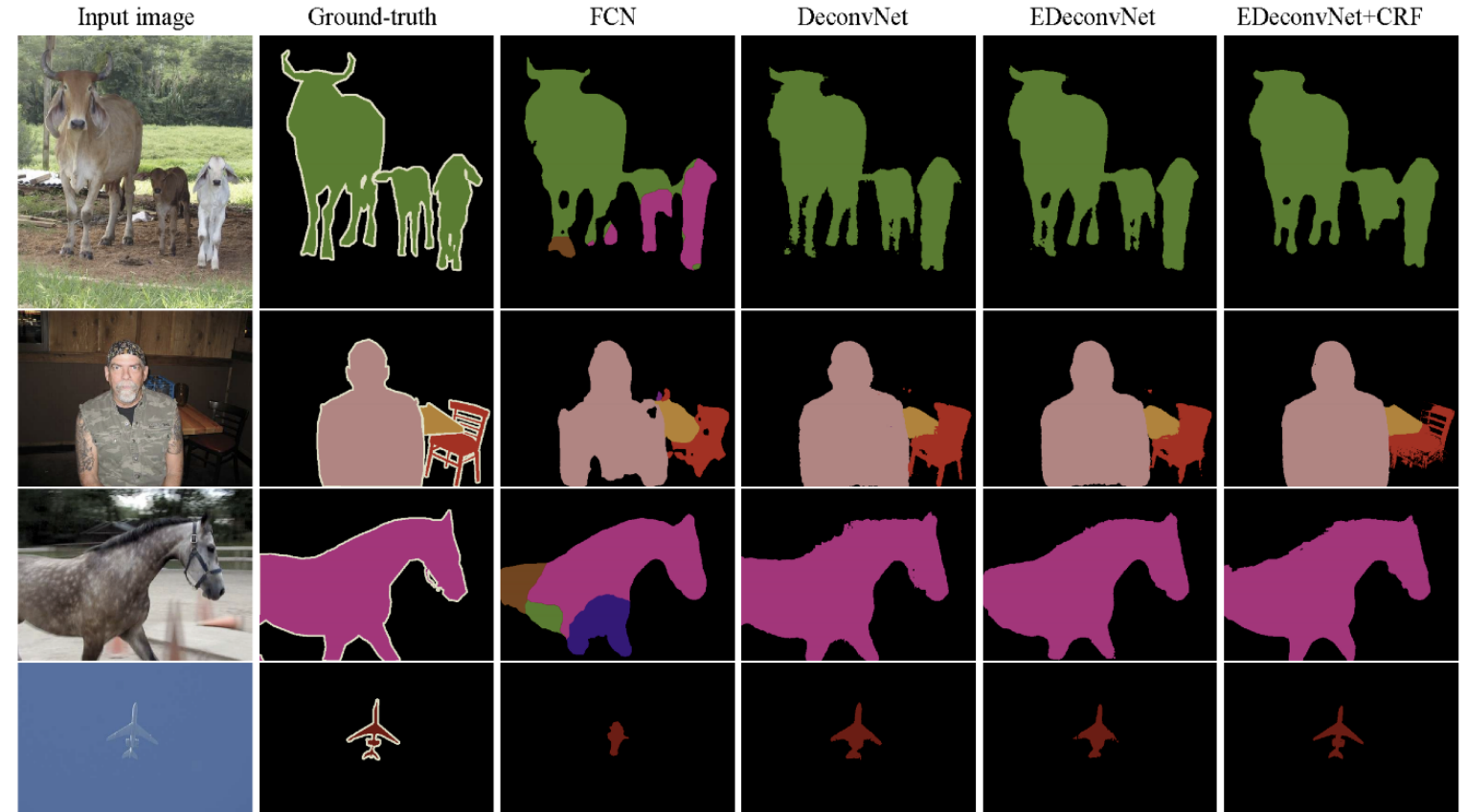
Detection
- R-CNN
region을 대충 있을곳 같은곳에서 뽑아서 CNN으로 계산으로 SVM으로 classify함

- SPPNet
RCN 에서의 문제는 뽑은 region을 전부 CNN에 넣어야함.
-> 이미지 안에서 한번만 돌려보자.
이미지 전체에 대해서 CNN에 넣고 나서 boundary 안에있는 tensor만 뽑아서 하자.
- Fast R-CNN
SPPNet과 동일한 컨셉.
마지막에 box 이동
- Faster R-CNN
bounding box를 뽑는것도 학습을하자.

sliding window 에서 안에 물체가 있을것 같은지?
RPN
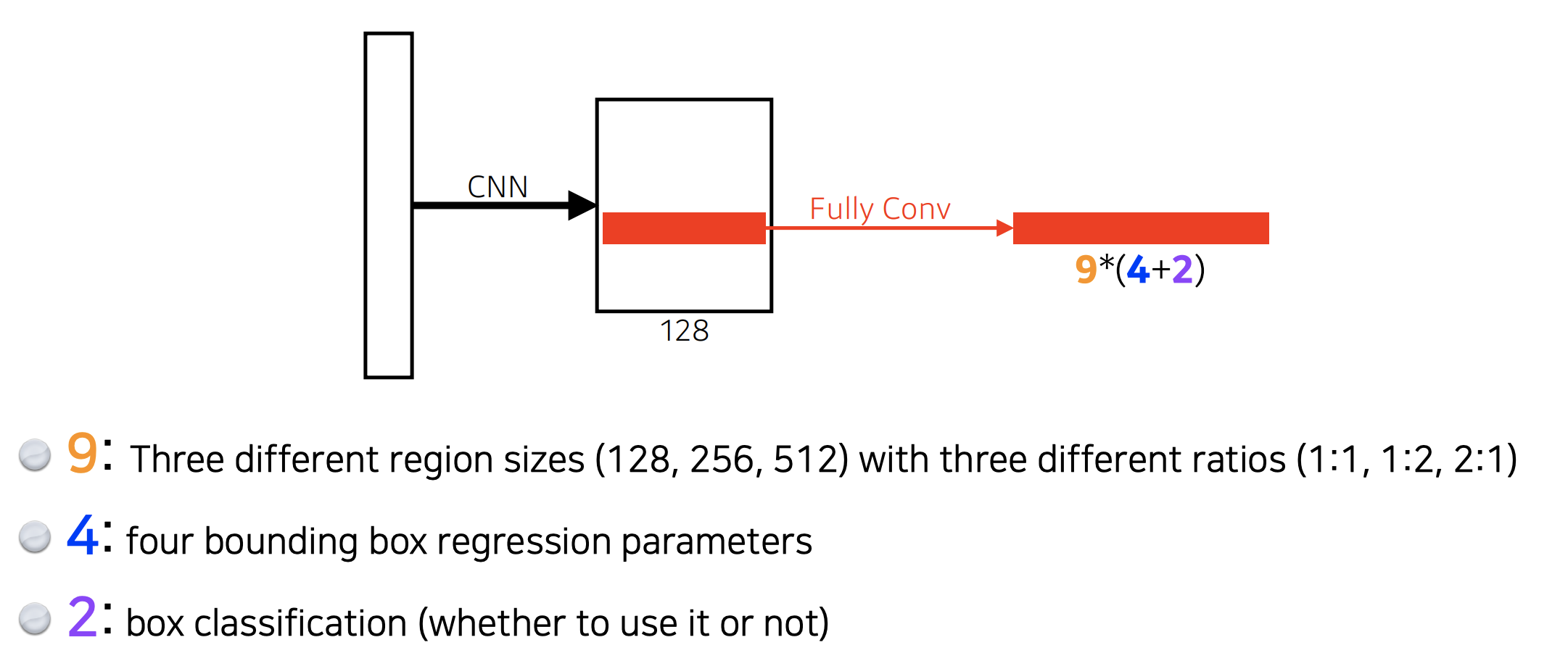
어떤 bounding box를 사용할지말지 찾아준다.
- YOLO (v1)
extremely fast object detection algorithm
그냥 이미지 한장에서 output을 뽑아줌
RPN 사용 X

S x S grid 로 쪼개줌.
bound 유효한지 + class map 동시진행
-> final detections
'DeepLearning > 부스트캠프 AI Tech' 카테고리의 다른 글
| Transformer: Attention is all you need (0) | 2021.08.12 |
|---|---|
| RNN(Recurrent Neural Network) (0) | 2021.08.12 |
| [Week2] DL Basic Optimization[Day2] (0) | 2021.08.10 |
| [Week2] DL Basic [Day1] (0) | 2021.08.09 |
| [Week1] Python Basics for AI & AI Math_Overview [Day5] (0) | 2021.08.08 |



