
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- NLP
- LLM
- GPT
- Deeplearning
- 알고리즘
- transformer
- deque
- 머신러닝
- rnn
- 프롬프트
- 부스트캠프
- 코테
- ChatGPT
- Programmers
- machinelearning
- BFS
- 코딩테스트
- dl
- Django
- 일기
- Linear Model
- prompt engineering
- gradient descent
- Python
- 프로그래머스
- attention
- 기계학습
- 파이썬
- Linear Regression
- LeetCode
Archives
- Today
- Total
크크루쿠쿠
[NLP] LSTM and GRU 본문
Long Short-Term Memory (LSTM)

기존 Vanilla RNN 에서 가지는 문제를 해결하기 위해 나온 model
기존 RNN 식에서 Ct 라는 변수가 추가됨 -> cell state
- i : input gate

sigmoid를 거치고 나옴
- f : forget gate

sigmoid를 거치고 나옴
element wise로 곱해줌으로써 얼만큼만 넘겨줄지
- o: output gate

sigmoid를 거치고 나옴
hidden state 만들 때 사용
- g : gate gate


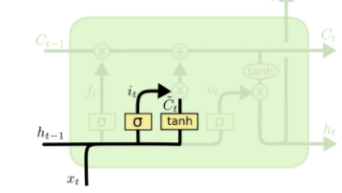
tanh를 거치고 나옴
input gate와 gate gate를 곱해 Ct를 구해줌
Gated Recurrent Unit (GRU)
What is GRU?
cell state vector와 hidden state vector를 일원화 하여서 hidden state vector만 존재한다.

input gate(z) 만 사용하고 forget gate는 1에서 뺀(1-z) 값 만을 사용한다.
Backpropagation in LSTM/GRU

덧셈 연산으로 인해 gradient의 큰 변환 없이 넘겨줄 수 있음.
Summary on RNN/LSTM/GRU
- RNNs 는 구도 디자인에서 매우 유연함
- Vanilla RNNs는 간단하지만 문제가 있음. -> gradient vanishing/exploding
- 그래서 LSTM이나 GRU 사용
'DeepLearning > 부스트캠프 AI Tech' 카테고리의 다른 글
| Beam Search and BLEU score (0) | 2021.09.13 |
|---|---|
| Sequence to Sequence with Attention (0) | 2021.09.13 |
| [NLP]Recurrent Neural Network and Language Modeling (0) | 2021.09.07 |
| [NLP]Word Embedding (0) | 2021.09.06 |
| [NLP]Intro to NLP, Bag-of-Words (0) | 2021.09.06 |
'DeepLearning/부스트캠프 AI Tech' Related Articles
more




Comments